
Your pharma marketing campaigns are approved. Your content is live. And the patients and healthcare professionals (HCPs) asking ChatGPT, Gemini, or Grok about your product right now are reading an answer your team never reviewed, from sources you didn’t select, in an order no one approved.
That is not a future risk. It is the current default behavior of the systems your audience is using to research treatment options. In January, OpenAI announced that more than 40 million health questions are asked in ChatGPT each week. Patients and HCPs aren’t scanning multiple sources anymore — they’re reading a single synthesized answer that determines what information is included and how it’s presented.
Pharma marketing teams approve content as a package. Claims, safety information, and use boundaries go through medical, legal, and regulatory (MLR) and pharmacovigilance (PV) review together. The assumption until now was that patients and HCPs will encounter that content in the order it was approved. Generative AI breaks that assumption.
What Resolver’s research found
Generative AI models don’t retrieve your content as you intended it to be discovered. They reconstruct it from whatever sources they find relevant, without preserving the structure your team approved. The issue isn’t simply whether the answer is accurate — it’s whether approved safety context stays attached to claims once AI systems reconstruct the response patients actually read.
That creates a monitoring gap for teams whose campaigns are already live across channels they can’t fully observe. Resolver’s research shows this behavior is already happening.
Resolver tested ChatGPT, Gemini, and Grok against pharmaceutical prompts spanning oncology, immunology, and virology, examining how each model handled off-label use, side effect profiles, patient preference questions, and safety framing.
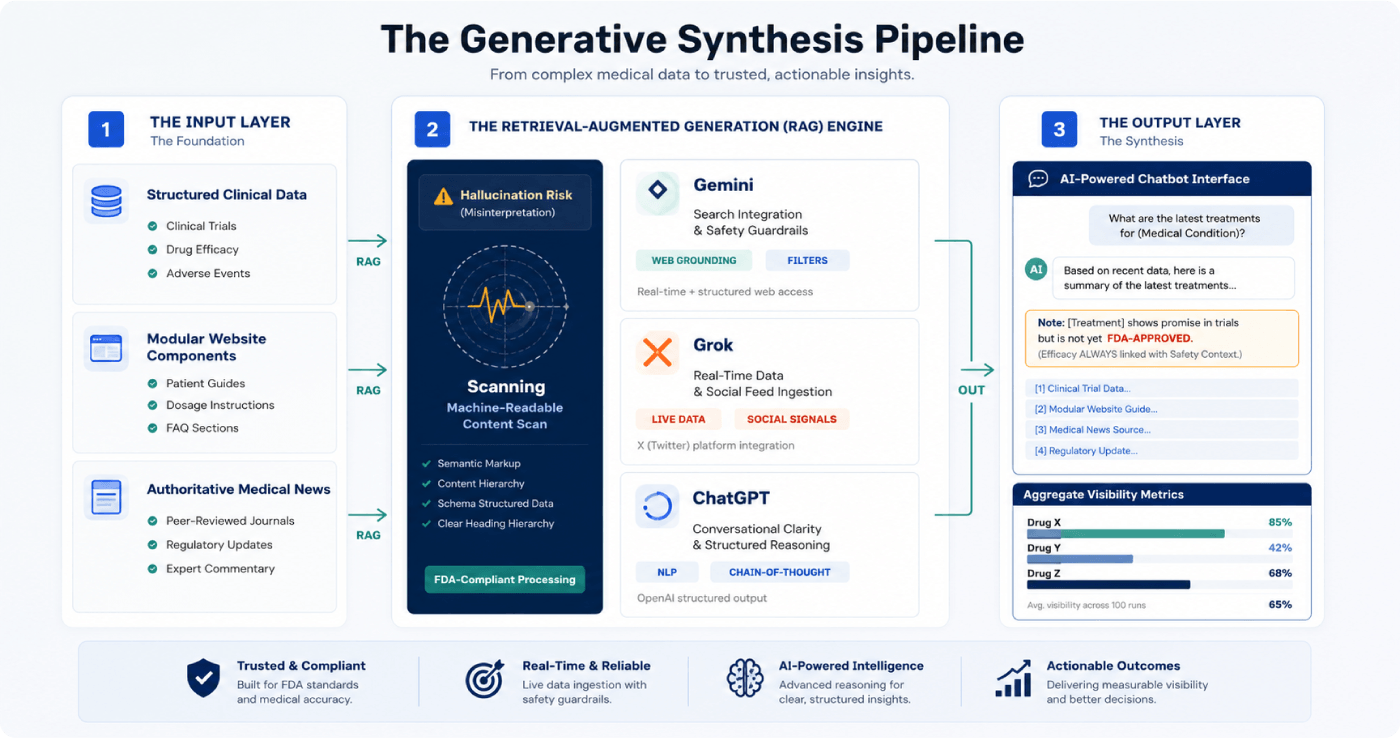
In one off-label query, the LLM model opened with “Yes” before clarifying two paragraphs later that the treatment was investigational. Across the dataset, the models repeatedly reordered approved information, separated safety qualifiers from claims, and blended clinical references with forum content inside the same response. The same prompt produced materially different sourcing and framing across all three models.
The failures followed three consistent patterns: accurate information presented in a different sequence than approved, safety qualifiers absent from outputs that read as complete, and clinical sources appearing alongside patient forum content without distinction.
What this changes for pharma marketing teams
AI-generated health answers change more than discoverability. They change how approved pharmaceutical information is interpreted after launch. Content can rank well in traditional search and still be absent from the AI-generated answer a patient actually reads. Safety context can exist online and still lose prominence once an AI system reconstructs the response.
Post-launch strategy can no longer end at content approval. The channels where patients and HCPs are now forming first impressions of your products aren’t channels your current monitoring infrastructure was built to observe. That affects how your team thinks about monitoring, visibility, content structure, and pharmacovigilance exposure across AI-mediated channels.
The question isn’t whether AI systems are reconstructing your approved content. The research shows they are. The question is whether your team has visibility into how — and whether your pharmacovigilance workflow accounts for what happens before a signal ever reaches your owned channels.
The intelligence your post-launch team is missing
This report is an example of the strategic intelligence Resolver provides to pharma marketing and communications teams. The same analytical approach — testing how AI systems handle your products, your indications, and your approved content across real prompts — is available as a structured briefing for your brand.
Generative Engine Optimization: How to Confront AI-Mediated Medical Queries documents findings from testing ChatGPT, Gemini, and Grok across ten pharmaceutical prompts. It includes side-by-side model comparisons, sourcing analysis, findings on how social platform signals altered model behavior, and recommendations for pharma marketing and PV teams assessing post-launch monitoring exposure.
The question isn’t whether this is affecting your brand. The research shows it already is. Download the report to see exactly how.


